杠杆炒股,股票融资!

跟着科技春晚CES 2025的召开,NVIDIA肃穆推出了搭载全新的Blackwell GPU架构的GeForce RTX 50系列显卡,该系列不仅在性能上碾压前代居品,更是通过AI和神经渲染本领,将游戏画质和互动体验提高到一个全新高度。今天,咱们就来深刻分解一下GeForce RTX 50系列显卡的那些“黑科技”,望望它到底有多“炸”!

Blackwell架构
Blackwell架构是本次更新的重心,以大卫·布莱克威尔,受东说念主尊敬的数学家和统计学家。布莱克威尔在博弈论和统计学方面的创始性服务和孝顺在该领域留住了不行隐没的钤记,使他的名字成为数学科学立异和超卓的代名词。这一致意反馈了新平台的创始性和先进的计较才智。它不错说是NVIDIA比年来更新幅度最大的GPU架构了,比较起之前的架构来说,划期间的引入了神经收集着色器,力求为游戏创始先进、高效更有传神的渲染方式,带给玩家全新的游戏体验。
据NVIDIA先容,在缱绻Blackwell架构时,就对其奉求厚望。绝对围绕新的神经收集功能和更低的功耗负载进行缱绻与优化,旨在减少举座的内存占用,提高动力使用效率以及引入新型服务品性功能。

省流转头:Blackwell架构上主要升级了第五代张量中枢,它能提供高速FP 4精度的计较才智和高达4000 AI TOPS的性能,另外,还升级了第四代RT(清明跟踪)中枢,专为Mega Geometry缱绻,能够提供高达360 RT TFLOP的性能。其中Mega Geometry是新一代AI照应处理器,可同期施行AI模子和图形服务负载。字据NVIDIA的先容,全新的Blackwell SM具有125 TFLOPS的峰值FP 32计较才智,同期成绩于GDDR7显存的应用,可已毕高达30 Gbps的速率传输,每一项齐是顶级的体验。

全新的SM多单位流处理器
接着咱们再细说一下这一代架构的变化,先从中枢来看,全新的Blackwell架构相较于RTX 40系的Ada架构照旧有不小变化的,Ada架构内的SM内,着色单位(也就是CUDA中枢)会拆分红一半成心用于处理FP 32(单精度浮点数),另一半则依需求动态诊疗去向理FP 32和INT 32(32位整数)。而在Blackwell架构上,着色单位则改成了绝对依需求动态处理FP 32和INT 32的时局。
另外还有一个修订是,过往的着色服务负载频频只好CUDA中枢处理,而Blackwell架构上引入了神经收集着色的方式,使得Blackwell架构上的第五代Tensor中枢也能共同分摊着色服务,大大提高了着色效率。
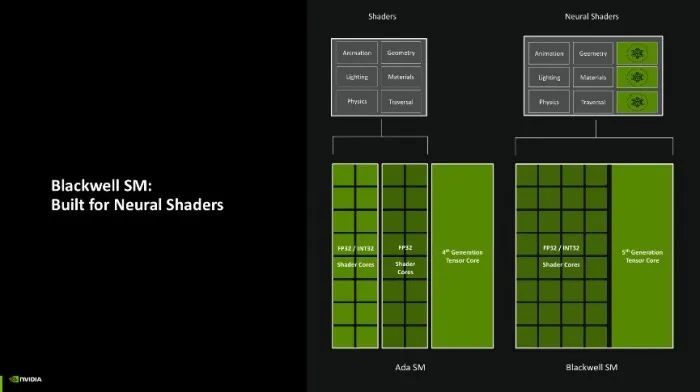
这么修订的平允是,Blackwell架构能够进一步针对神经收集着色服务负载进行排序,即把传统的着色服务分派给CUDA中枢,而需要动用神经收集运算的服务负载则不错给到Tensor中枢上,两种中枢同期行使,能够将举座的再行排序效率提高2倍。
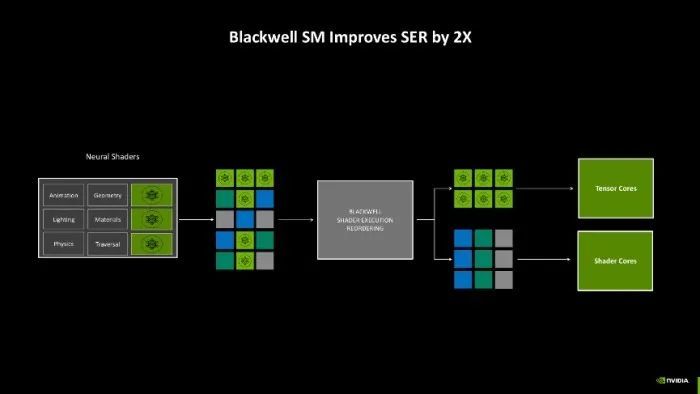
第五代Tensor中枢
第五代Tensor中枢除了能够加快再行排序,它还支撑FP 4精度模子的加快处理,相较于Ada架构上的第四代Tensor中枢支撑FP 8精度模子,隐晦量整整提高了2倍!要是对比Pascal架构的中枢隐晦量的话,提高幅度高达32倍!成绩于第五代Tensor中枢的引入,这才让DLSS 4能够已毕逆天的多帧生顺利能。
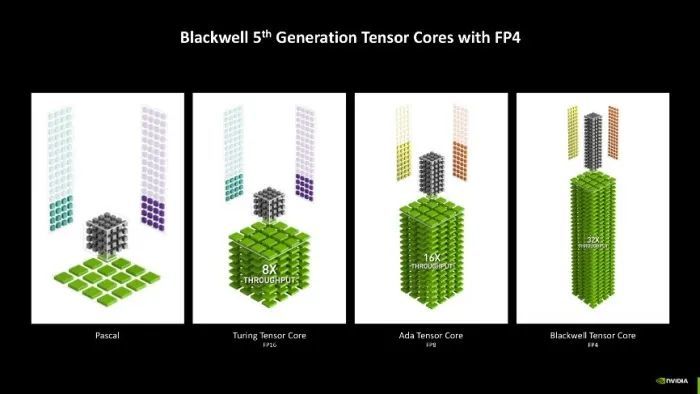
字据NVIDIA的实测,给与FP 4精度去生成团结张图良晌,不仅生成速率更快,同期显存占用也更少,相较于传统的FP 16精度,FP 4精度最多不错已毕2倍以上的性能提高,以及量入计出50%的显存铺张。

第四代RT中枢
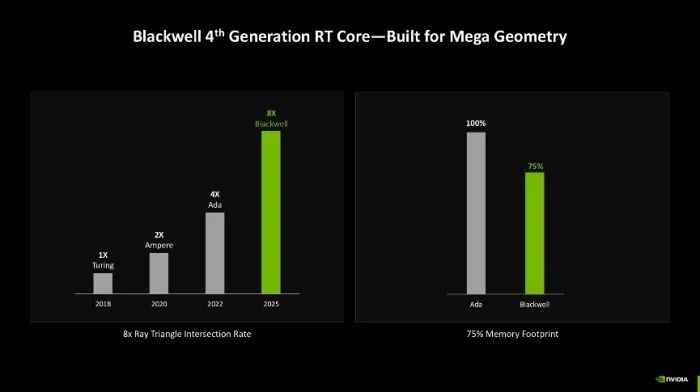
第四代RT中枢也有跨越,相较于第三代RT中枢来说,Blackwell架构的第四代RT中枢支撑原有的Box Intersection Engine和Opacity Micromap Engine,不外把原有的Triangle Intersection Engine扩张成Triangle Cluster Intersection Engine,再加入 Triangle Cluster Decompression Engine 和 Linear Swept Spheres。说东说念主话就是过往的三角形相交引擎升级为三角形簇相交引擎,该引擎针对Mega Geometry进行了优化,不错更灵验地处理Mega Geometry和标准几何体的簇。
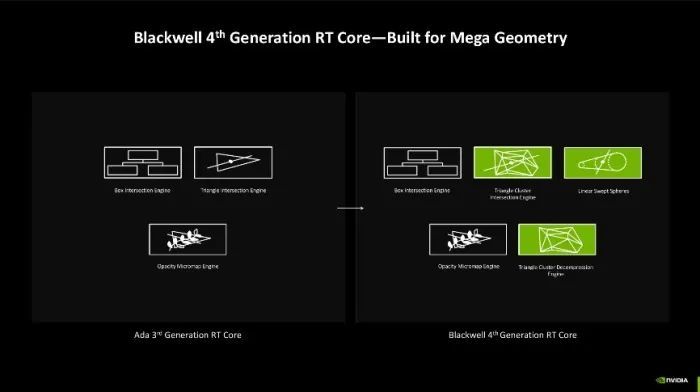
同期Mega Geometry引擎还具有新的三角簇压缩方式,详尽来看,Blackwell架构的清明跟踪多边形相交效率是上一代Ada架构的2倍,是Turing架构的8倍,同期显存使用率却只好Ada架构的75%。
先进的AI照应处理器
此外,AI必将是改日的重心之一,游戏中应用AI本领的情况越来越多,而怎样去分派显卡里面各类化服务就成了一个问题。举例过往显卡在开启DLSS玩游戏时,其中应用到的话语模子和游戏引擎需要同期与GPU的不同中枢交互,生成游戏帧,但是频频很难作念到每一帧齐有一致的生成时间,亦或者是游戏AI对话的响应不够实时,这些情况齐会形成游戏体验不友好。
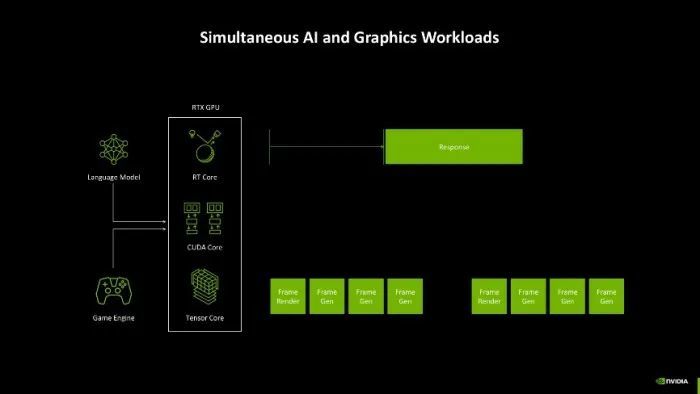
而AI照应处理器(AMP)的出现,就是贬责这些问题的要津。它能够实时转化资源,确保在神经渲染、帧生成和 AI 驱动的游戏交互中已毕智能化的任务分派。这种缱绻不仅带来了更高效的性能输出,还让显卡在游戏渲染和 AI 运算之间已毕了绝佳的均衡,确保帧的断绝均匀,对话类型的AI能够实时响应,玩家的游戏体验一致性能够比较好的保险。
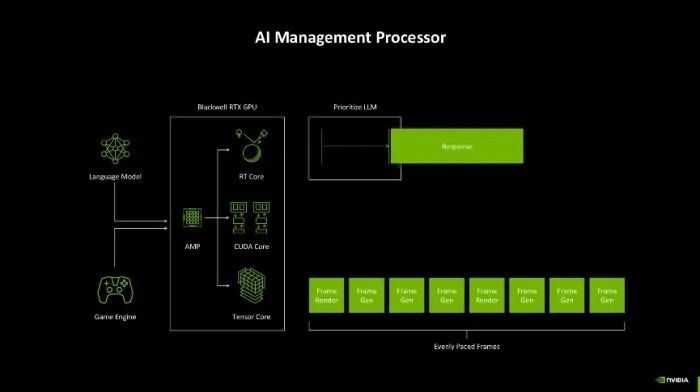
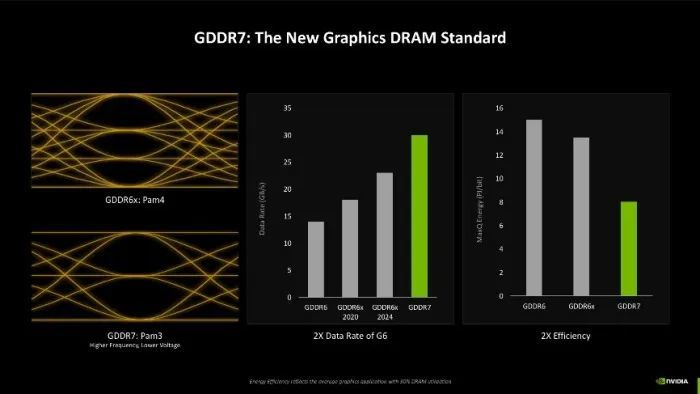
首发GDDR7显存
显存方面相通是更新的重心,前两代Ampere和Ada架构的GPU均使用的是GDDR6X显存,其信号给与PAM4编码,而这一代Blackwell架构的GPU首发最新的GDDR7显存,而且信号编码改成了PAM3,这么不错使杂讯失真比较小,信号品性更清醒,同期也能带來更高的显存运行频率以及更低的电压,字据NVIDIA的先容,使用GDDR7显存后,数据传输速率可达GDDR6时的2倍,而且功耗接近GDDR6的一半,经典加量还减价。
第9代编码器与第6代解码器
关于创作家而言,Blackwell架构也迎来了更全面的视频规格支撑,GeForce RTX 50系列显卡上将换装第9代编码器与第6代解码器,支撑AV1 UHQ(超高画质 AV1)与MV-HEVC(多视角HEVC)编解码。
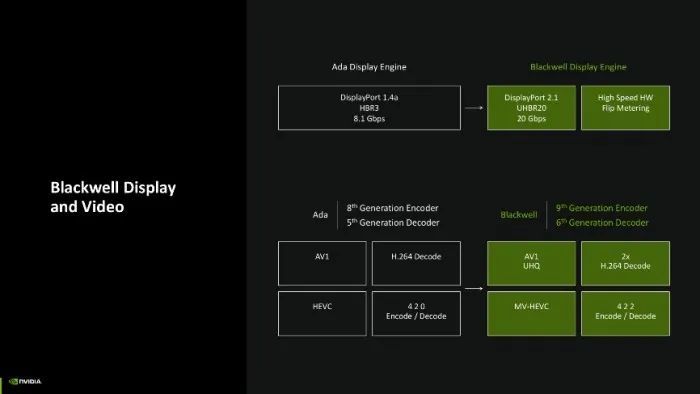
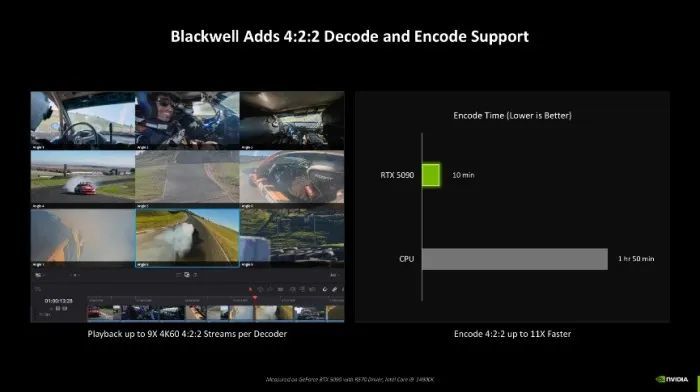
另外Blackwell架构也终于能够已毕4:2:2色度取样的视频编解码,相较于4:2:0来说,它能够记录更多的颜色信息,提高画面品性。同期披露输出引擎也同步升级至 DisplayPort 2.1 UHBR20,单一通说念可已毕20Gbps的带宽,单一线材具备4通说念即可达80Gbps的才智。

速率上,相通是4:2:2的视频编解码,给与RTX 5090能够比平直用CPU编解码快整整11倍以上。
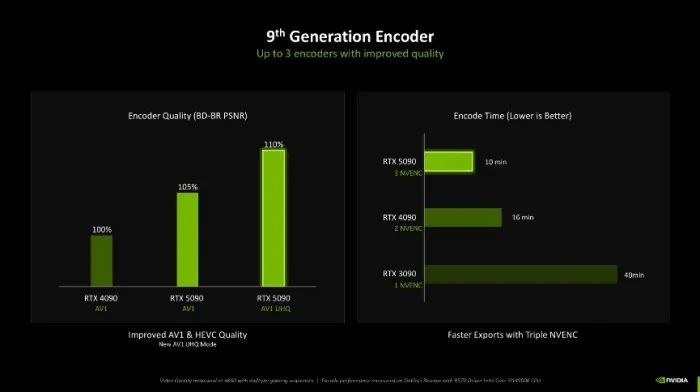
同期,Blackwell架构中RTX 5090配备了三个第九代编码器,编码效率比较上代显卡亦然史诗级跨越,能够大大提高创作家的效率。
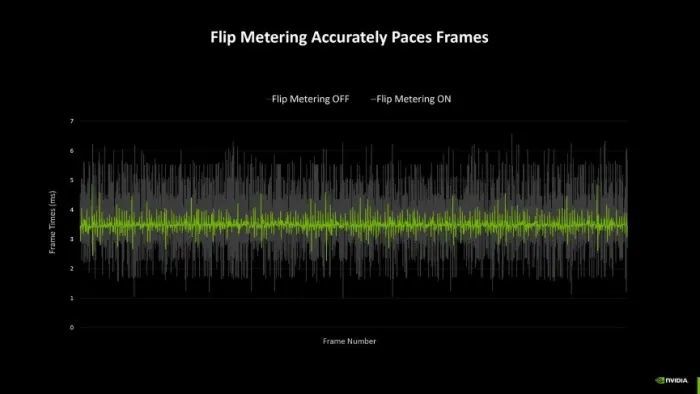
另外,Blackwell架构GPU还引入了用于检测骨子画面输出延伸的Flip Metering,输出更雄厚的同期,也为多帧生成本领提供数据支撑。

出色的节能缱绻
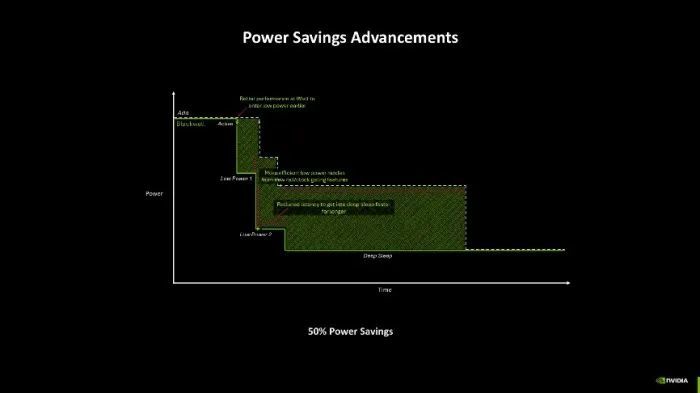
性能硬件上的提高照旧鼓胀出色了,Blackwell架构还在电源效率险峻功夫,领有先进的节能缱绻,而且这些节能缱绻并不单是局限于过往条记本或MAX-Q版块,台式机也能享受这些节能红利。

当先是闲置运算单位的部分,NVIDIA为Blackwell开发了新的电源限制模式——Rail Gating,轻便来说就是不错单独微调显卡里面不活跃部件的供电情况,即要是你的存储暂时没用,或者你的部分中枢暂时没用,则不错通过诊疗这部分的电源供应,已毕节能的效率。

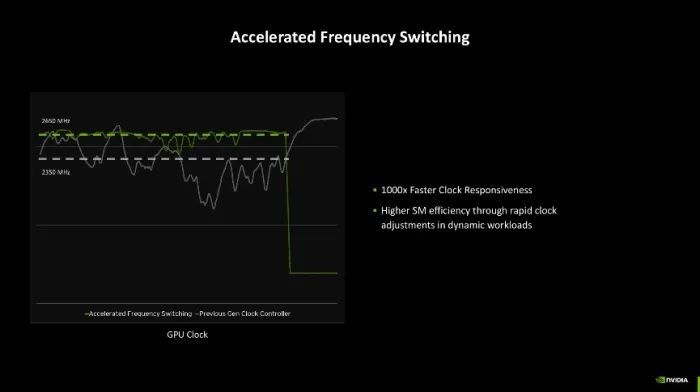
另一种省电的次第是Blackwell的频率切换速率比Ada架构时提高了上千倍,即等于插足低电源情状的就寝、叫醒速率也提高了数个量级。成绩于上头这些性格,当今Blackwell GPU着力更好,可更早完成服务负载并插足低功耗情状,而在有负载时,凭借更快的频率切换速率也能更快的提高性能开释,同期也不错针对性的供电,让一些不活跃的中枢也能保管在低功耗情状,从资料毕更灵验的电源利用。字据NVIDIA的先容,这么至少能够简略50%的电源铺张。
·本领分解:DLSS 4
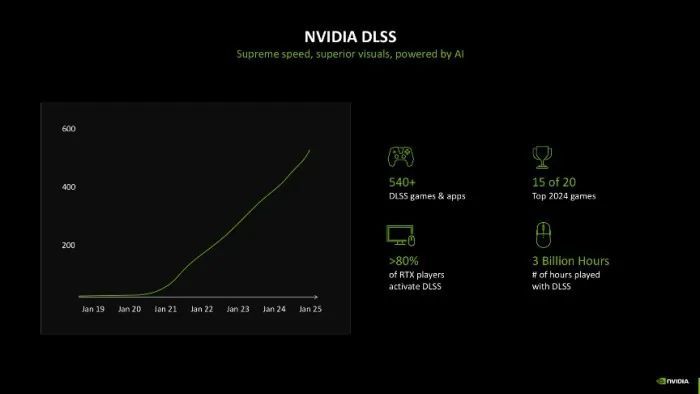
先容完NVIDIA引认为傲的RTX神经渲染,再让咱们望望应用RTX神经渲染的最好例子——DLSS。它不仅能提高帧率,还可同期提供清醒是非的高质地图像,效率与原生区分率渲染忘形。咫尺支撑DLSS的游戏照旧多达540款,而玩家使用DLSS的时间更是长达3亿个小时,不错说DLSS给玩家带来了划期间的游戏体验。
咫尺DLSS照旧迭代至DLSS 4,DLSS 4进一步整合了多帧生成 (Multi Frame Generation)、清明重建 (Ray Reconstruction)和超瓜区分率 (Super Resolution)等多种先进本领,通过 AI 模子对帧间信息进行深度分析与和会,最终呈现出更具千里浸感与真的感的画面。
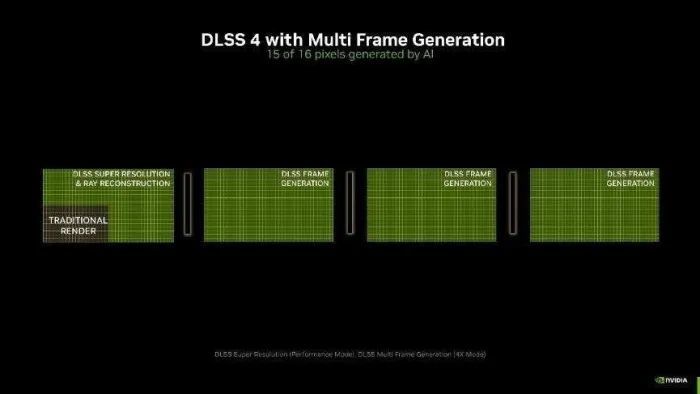
什么是DLSS 多帧生成?
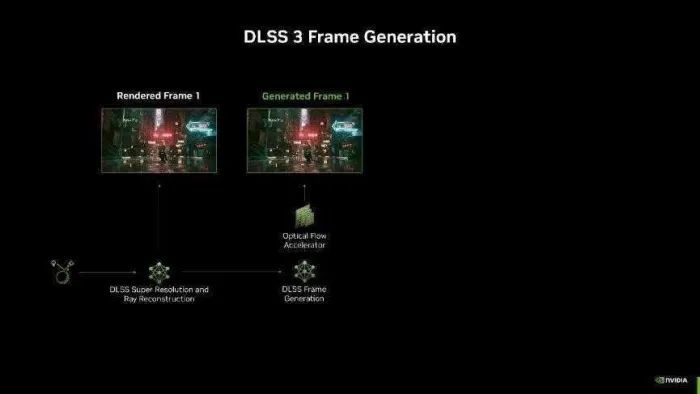
在 DLSS 3 帧生成本领中,AI 模子使用指导向量和深度等游戏数据以及来自 GeForce RTX 40 系列光流加快器的光流场来生成一个额外的帧。由于每生成一个新的帧齐需要光流加快器和 AI 模子参与,因此生成多帧的支出特地文明,而过高的性能支出会带来瓶颈,导致帧率提高受限。
而DLSS 4则引入了多帧生成本领,由 GeForce RTX 50 系列和第五代 Tensor Core 提供支撑,利用 AI 可为每个渲染帧额外生成多达3帧!通过对前后帧的分析,准确预计出每一帧的变化,并利用AI本领生成高质地的图像,可已毕传统渲染8倍的性能提高。
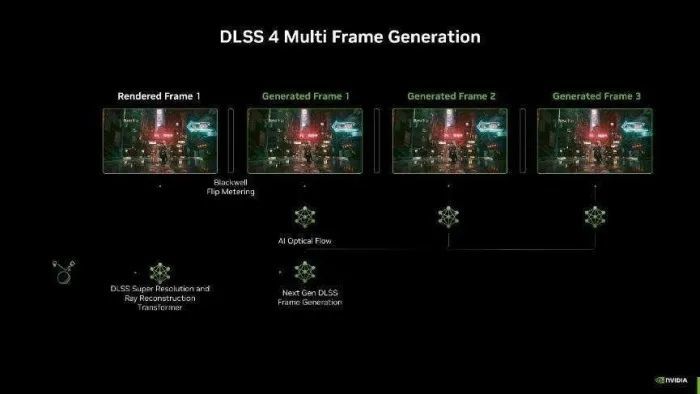
DLSS多帧生成本领还会与 DLSS 清明重建和DLSS超区分率等其他本领协同服务。清明重建本领不错字据生成的多帧更好地处理清明跟踪效率,使清明效率愈加传神和天然;超区分率本领则不错在多帧生成的基础上,进一步提高画面的区分率和细节,确保在高帧率下画面质地也能保执较高水平。
另外,由于多帧生成本领,为了防备画面效率变差,NVIDIA还引入了专属的Flip Metering来代替CPU Pacing,它将帧节律逻辑迁移到披露引擎,让GPU能够更精确地照应披露时间,尽可能的将每一帧画面的生成时间保执一致,从而提高举座游戏视觉的通晓感。
新Transformer模子架构
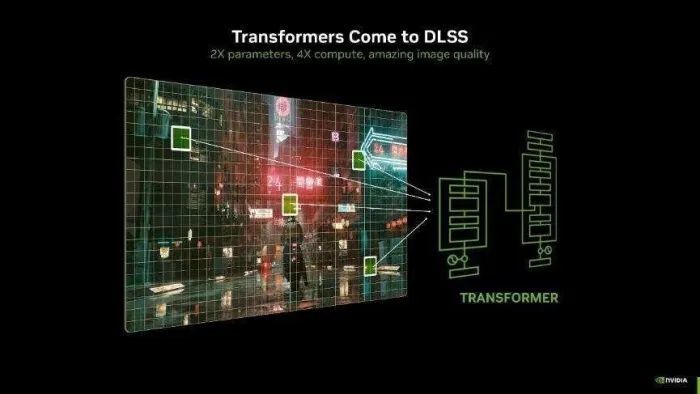
DLSS 4 还引入了图形行业首个 Transformer 模子实时应用。基于Transformer架构的 DLSS 超区分率和清明重建模子,比较卷积神经收集(CNN)模子来说,具备2倍的参数目和4倍的计较量。在游戏场景中,能够提供更高的雄厚性、更少的拖影、更高的细节和更强的抗锯齿才智,使画面愈加清醒、通晓和传神。
不外天然DLSS 4的多帧生顺利能是RTX 50系显卡的独占功能,但新的Transformer模子将会冉冉下放至DLSS 3、DLSS 2等,将适用于总共GeForce RTX显卡。

Transformer 模子的最大上风在于其庞大的全局分析才智。传统的卷积神经收集(CNN)在单帧优化上证实出色,但对动态场景中的复杂变化(如快速转移物体或清明变化)处理有限。而 Transformer 能够捕捉多帧之间的时间掂量和全局场景信息,从而愈加精确地复原细节,进一步减少“拖影”快意,造福更多的游戏玩家。

显存占用优化
同期成绩于多帧生顺利能是利用效率极高的AI模子,相较于上一代的硬件光流器进行帧生成的方式,能够权贵缩小生成额外帧的计较支出。反应在披露中就是能够简略显存占用,举例在《战锤 40 K:暗流 》中,以4K最高斥地游玩,DLSS 4不仅可将帧率再提高10%,还能将内存占用量减少400 MB。

卓绝75款游戏和应用支撑DLSS 4
DLSS 4首发今日照旧支撑卓绝75款游戏和应用标准,包括《赛博一又克2077》《战神:诸神薄暮安纳琼斯与大圈》《沙丘:醒悟》《铲除战士:昏黑期间》等,《黑传奇:悟空》将于本年晚些时候升级支撑 DLSS 多帧生成。跟着时间的推移,支撑DLSS 4的游戏和应用数目将不断增多。

关于尚未完成更新至最新DLSS模子和功能的游戏,NVIDIA App将通过全新DLSS优设功能已毕掂量支撑。说东说念主话就是,要是你想玩的游戏还莫得提供DLSS,你不错通过NVIDIA App进行斥地,强开DLSS本领,操盘同期跟着NVIDIA驱动的不断更新,DLSS掂量的AI模子也会封装在驱动之中,跟着模子的不断迭代,画质与性能也会越来越好,轻便的说DLSS越用越好用!
不外DLSS 4本领中的多帧生顺利能咫尺仅支撑最新的GeForce RTX 50系列显卡。究其原因照旧因为多帧生成需要Blackwell架构内置的增刚毅件翻转计量功能,这项功能不错提供通晓、高质地体验所需的速率和准确性。因此想要体验最新的黑科技,还需要玩家更新至GeForce RTX 50系列显卡才行。

·本领分解:NVIDIA Reflex 2
延伸是电竞中长久绕不开的话题,玩家的每个当作齐会经过复杂的计较,再在屏幕上渲染,这其中的每一步齐会增多延伸。天然延伸频频只好几十毫秒,但是你却能显着的嗅觉到游戏的不通晓、卡顿。
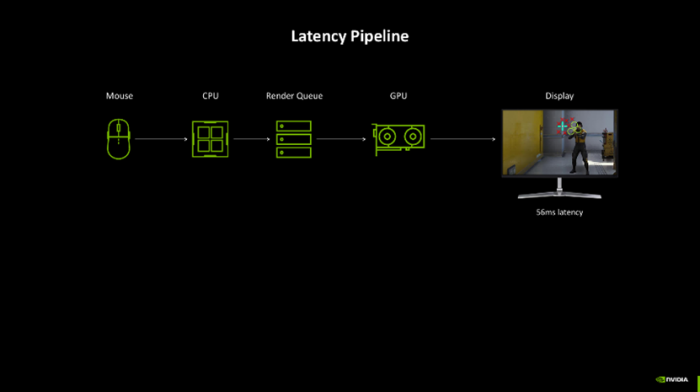
为了尽可能的缩小延伸所带来的不良游戏体验,NVIDIA发布了NVIDIA Reflex本领,它不错使GPU和CPU同步,确保最好响应速率和低系统延伸。

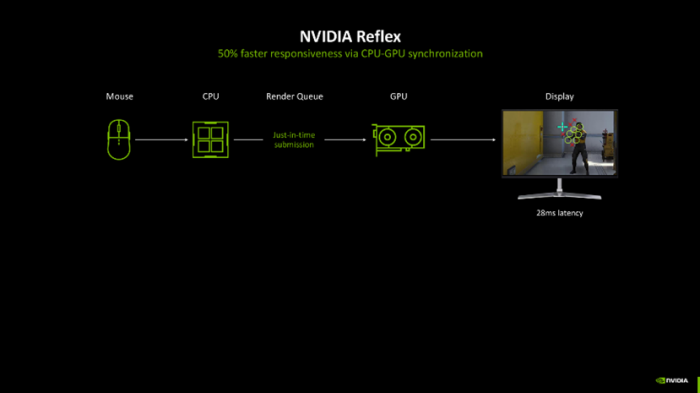
NVIDIA Reflex本领照旧鼓胀厉害了,不外新一代缩小游戏延伸的本领NVIDIA Reflex 2还有黑科技!Reflex 2将Reflex低延伸模式与新的Frame Warp本领相斡旋。在GPU渲染现时帧的同期,CPU会字据最新的鼠标或限制器输入计较出下一帧的相机位置。Frame Warp本通晓在GPU渲染的帧行将发送到披露器之前,尽可能晚地对其进行采样,并字据CPU计较出的新相机位置对该帧进行诬告诊疗,从而将最新的玩家输入反馈到屏幕上,延伸最高可缩小75%!
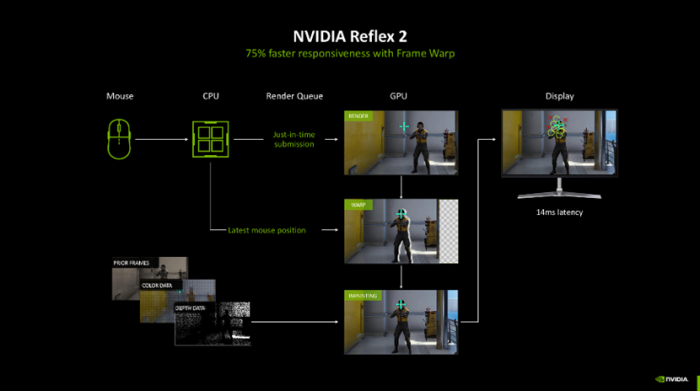
首发支撑NVIDIA Reflex 2本领的游戏是《THE FINALS》以及《丧胆公约》,该本领也将在 GeForce RTX 50 系列 GPU 上初度亮相,天然后续也会冉冉灵通给更多的GeForce RTX系列显卡,老玩家也不错体验到最新的本领。

·本领分解:RTX神经渲染
要是说硬件架构的升级照旧让东说念主感到振奋,那么Blackwell架构的GeForce RTX 50系列显卡在神经渲染领域的突破则号称“黑科技级别”。神经渲染(Neural Rendering)是 NVIDIA 对传统渲染方式的一次颠覆,它通过神经收集平直参与到图像的生成中,不再依赖单纯的硬件算力,而是通过智能算法已毕了画质与性能的双赢。
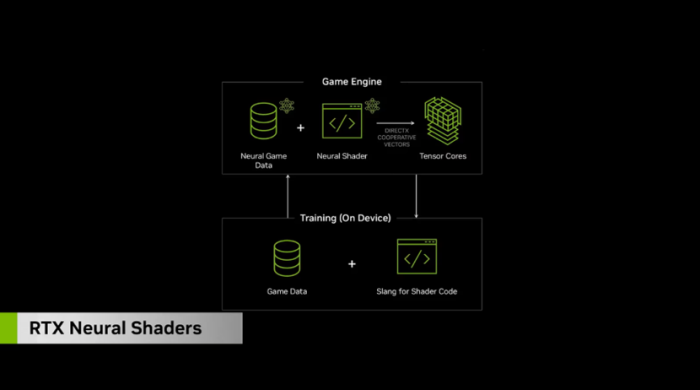
自2001年NVIDIA推出首款GeForce 3显卡以来,跟着披露API(Direct X)的不断更新,着色本领也不断发展,不断加入更高阶API的支撑以及清明跟踪功能,不外,跟着Blackwell架构的出现,一切齐迎来了要紧变革, Blackwell将Shader Core和Tensor Core进行了整合,创始性的引入了神经收集渲染器。
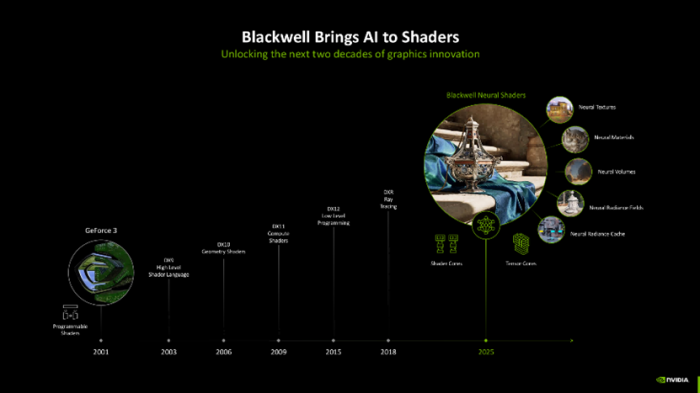
神经渲染你听起来简略有些目生,但要是我说DLSS 本领中的 Upscaling 超分解度放大,你可能就能够和会了,这其实就是一个轻便易懂的神经渲染应用实例。该本领通过较低输入分解度的渲染画面,借助神经收集拓展成高分解度画面,从而在不增多硬件服务的情况下,权贵提高画面的清醒度和细节证实。
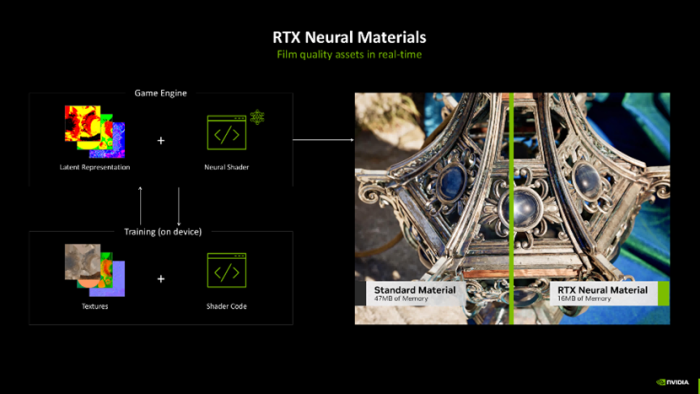
在Blackwell架构中,NVIDIA 进一步拓展了神经渲染的范畴,引入了诸多立异元素,包括神经纹理(Neural Textures)、神经材质(Neural Materials)、神经体积云(Neural Volumes)、神经发射场(Neural Radiance Fields)以及神经发射缓存(Neural Radiance Cache),这些元素共同组成了神经渲染中神经收集着色的要紧呈现方式。
夙昔复杂的物品或大宗异材质的贴图频频会占用特地大的内存空间。但是,成绩于神经收集渲染本领中的RTX Neural Materials材质功能,这一问题得到了权贵改善。RTX Neural Materials通过在游戏引擎端斡旋Latent Representation和Neural Shader,权贵缩小了骨子生成的材质数据量,从而在占用更少披露内存的同期,已毕了细节更丰富的材质证实,达到了实时生成如电影般细致素材的效率。
骨子效率如下,举例神经发射缓存不错利用经过游戏数据考验的神经收集,更准确且高效地预估游戏场景的波折照明。只需跟踪一两条清明并将其存储到缓存中,便能揣摸出无尽多条清明和反射情状,从而更精确地展现游戏场景中的波折照明效率。同期由于需要跟踪的清明数目大幅减少,举座性能证实也权贵提高,游戏帧数也会更好意思瞻念一些。

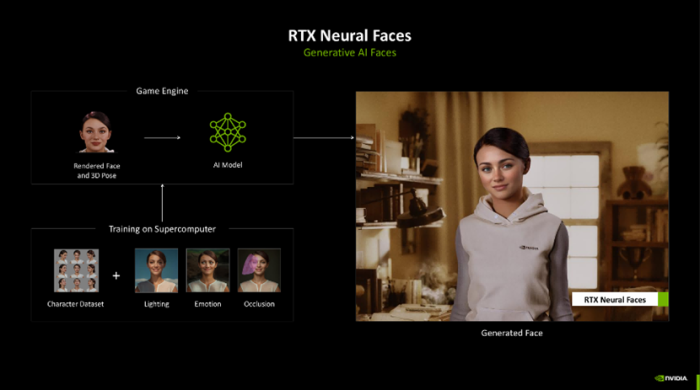
东说念主像亦然神经收集渲染的重心之一。传统的东说念主脸渲染方式与践诺之间存在一些狭窄的偏差,这些偏差积聚起来很容易让扮装不够真的,总有种AI的嗅觉。而 RTX Neural Faces 不错通过 AI 计较斡旋 3D 姿态数据,生成更天然的面部面目和当作,非凡是在扮装互动和剧情证实上,透顶摧毁了传统渲染本领的限制。
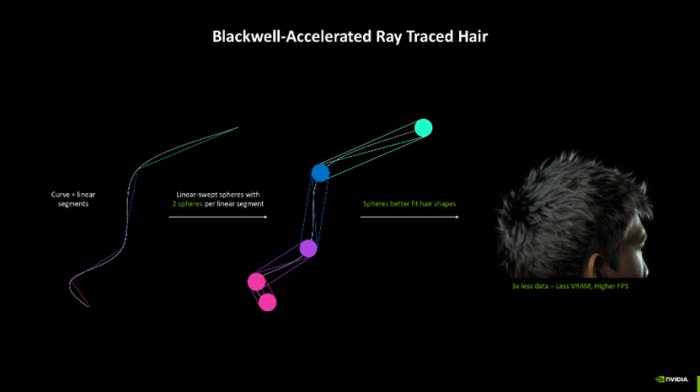
除了东说念主脸渲染外,头发渲染也一直是传统电脑图形学中的波折,因为每根头发齐需要大宗的多边形来构建,举例一位男士的头发可能需要多达400万个三角形,再加上清明跟踪本领,画面所需要的运算负载极大。NVIDIA则通过Linear - Swept Spheres(线性扫描球体)本领灵验减少了渲染头发所需的几何体数目,以球形代替多边形,更贴合头发的方式,从而将内存占用量大幅缩减至三分之一,并进一步提高了骨子帧数,让头发的渲染效率愈加天然通晓。

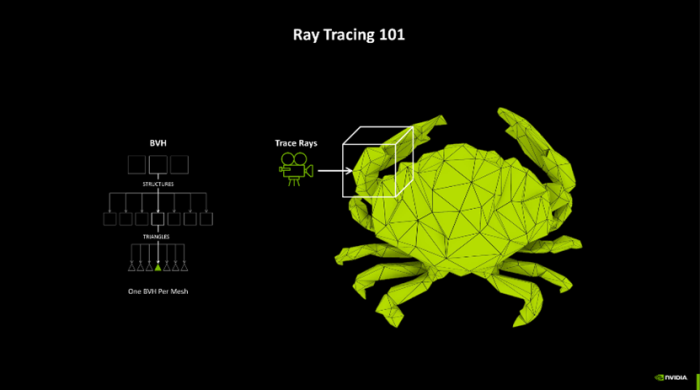
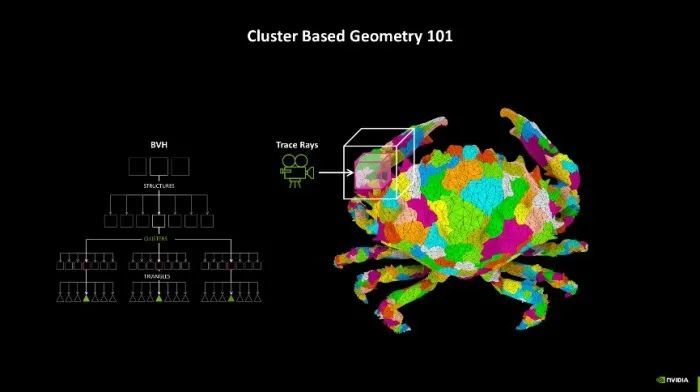
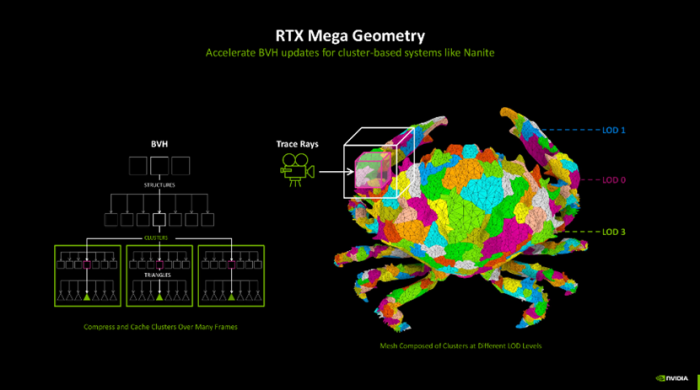
另外,跟着清明跟踪游戏场景的几何复杂性不断增多,游戏画面中几何图形的计较量也呈现出快速增长的趋势。因此NVIDIA还推出了RTX Mega Geometry本领,这项本领能够加快构建范畴体积端倪结构(BVH),使得在实时渲染中不错处理多达100倍的三角形数目。
该本领的出现,也使得开发者能够在游戏场景中使用更复杂的几何图形,而不会影响游戏帧率。夙昔需要一个个算BVH,当今RTX Mega Geometry能够智能地在GPU上批量更新三角形簇,减少了CPU的服务,既保证了性能,也兼顾了图像质地。驯顺跟着这些本领的不断发展和应用,改日的游戏将能够呈现出愈加传神和细致的视觉效率,同期保执高效的性能证实。
·NVIDIA RTX AI PC与NIM平台
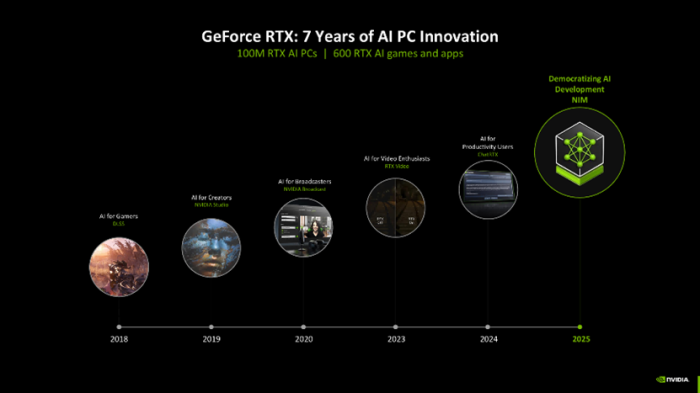
临了咱们再聊聊时下热点的AI PC,NVIDIA在AI PC领域其实照旧布局多年,早在2018年就照旧初始,7年时间,NVIDIA GeForce RTX在鼓动AI本领发展和应用方面执续发奋,不断探索AI本领在不同领域的粗俗应用和改日发展趋势。
当今,NVIDIA推出了全新的NIM for RTX平台,其专为GeForce RTX显卡优化,具备多项特点以提高AI部署的便利性和性能。当先,该平台给与容器化本领,简化了部署历程,使得开发者能够猖狂地在不同环境中部署和运行AI模子。其次,NIM for RTX针对GeForce RTX显卡进行了非凡优化,确保了在这些高性能显卡上运行AI模子时能够得到最好性能。

此外,NIM for RTX提供了业界标准的API,使得开发者不错利用这些API猖狂地集成和扩张AI功能。平台还包含了领域特定的代码,这些代码针对特定AI领域进行了优化,以提高模子的准确性和效率。NIM for RTX还支撑定制化,允许开发者字据我方的需求诊疗和优化模子。

在推理后端方面,NIM for RTX提供了庞大的支撑,确保了模子推理的高效和准确。初期推出的NIM for RTX照旧秘密了多种AI领域,包括话语处理、视觉话语、RAG(Retrieval-Augmented Generation)、演讲、动画、计较机视觉和图像处理等。跟着本领的不断发展,NVIDIA还研究连续优化现存模子并推出新款NIM,以得志不断变化的阛阓需乞降提供更粗俗的AI应用支撑。

同期,RTX NIM还不错与各类顶级AI器具相妥洽使用,用户构建和定制聊天机器东说念主、AI代理和创意服务历程将变得愈加容易。同期玩家还不错通过图形用户界面(Graph UI)和聊天用户界面(Chat UI)与AI进行互动,利用模子调优器具来优化AI模子的性能,举座可玩性更高,也展示了RTX NIM平台的丰富性。
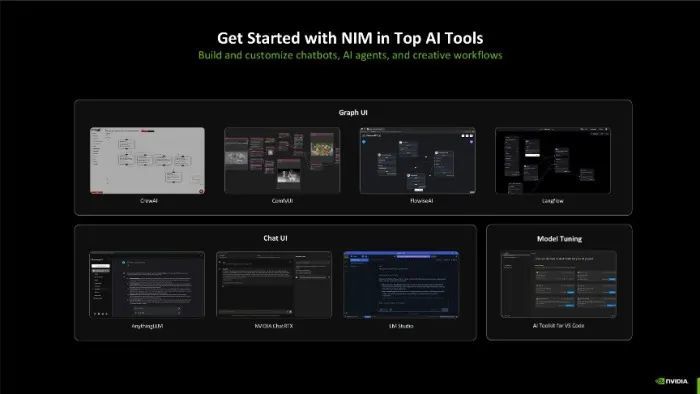
NVIDIA也展示了一些可用的场景,举例NIM不错将静态的PDF文档迁移为动态的播客内容。用户不错已毕从PDF中索求文本、生成转录本、生成播客以及通搅扰答标准与播客主执东说念主互动。这么不仅提高了内容的可探询性和眩惑力,还为内容创作家提供了一种新的内容创作和分发方式,常识和信息的传播愈加粗俗和灵验。

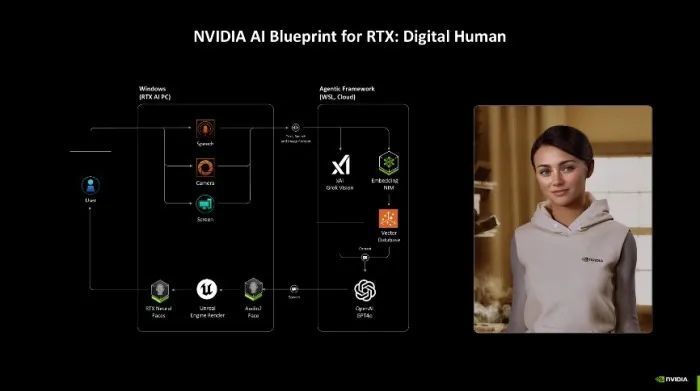
另外NIM还不错已毕数字东说念主AI功能,通过集谚语音识别、面部面目捕捉和向量化处理等本领,数字东说念主能够与用户进行天然和直不雅的交互。这些数字东说念主不仅不错用于文娱和训诫,还不错在客户服务、臆造助手和在线会议等领域证实要紧作用,为用户带来愈加丰富和个性化的体验。
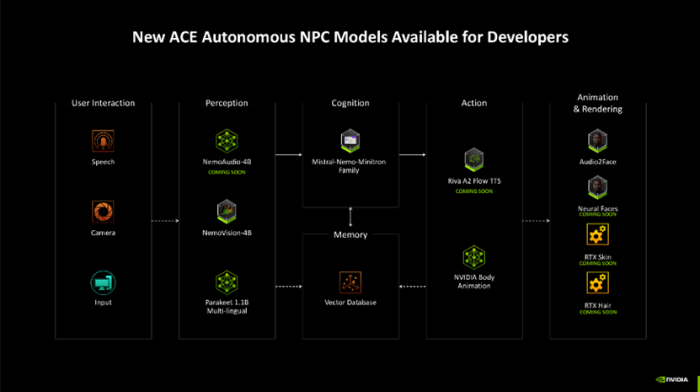
游戏领域:AI 驱动的 NPC 与互动体验
RTX NIM在游戏领域的应用也尤为引东说念主详确。通过 NVIDIA 的 ACE(AI Co-playable Characters)本领,游戏开发者不错为游戏中的 NPC(非玩家扮装)赋予更东说念主性化、更具互动性的缱绻。
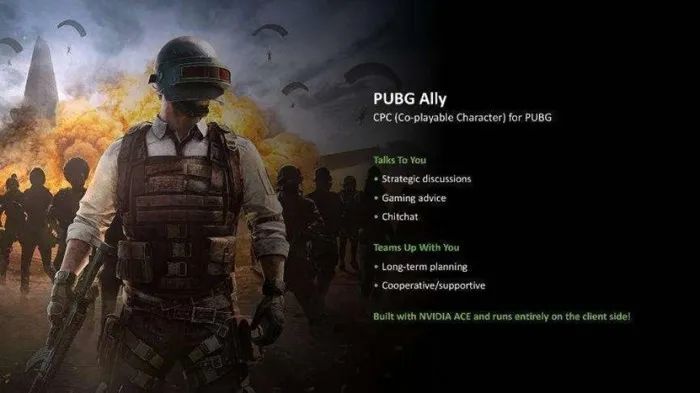
举例,PlayerUnknown’s Battlegrounds(绝地求生)行将推出的 PUBU Ally 功能,就是由 AI 驱动的队友功能。玩家不错通过天然话语与队友进行筹商,指挥队友施行各类战术当作,如将船舰再行漆成紫色等。这种 AI 驱动的 NPC 不仅能够接洽计谋、提供提出,还能与玩家进行日常的座谈,为游戏增添了更多的意念念性和互动性。
另一款 inZOI 生计模拟类游戏也利用了 RTX NIM 和 ACE 本领,使游戏内的扮装具备了自主念念考和方案的才智。这些扮装不错在早上起床后自行安排一天的生计,对各类事件作念出反应,并通过天然话语与玩家进行筹商。玩家甚而不错定制扮装的个性、掂量和牵记,使每个扮装齐具有独到的性格和布景故事。

直播领域:智能助手与直播体验升级
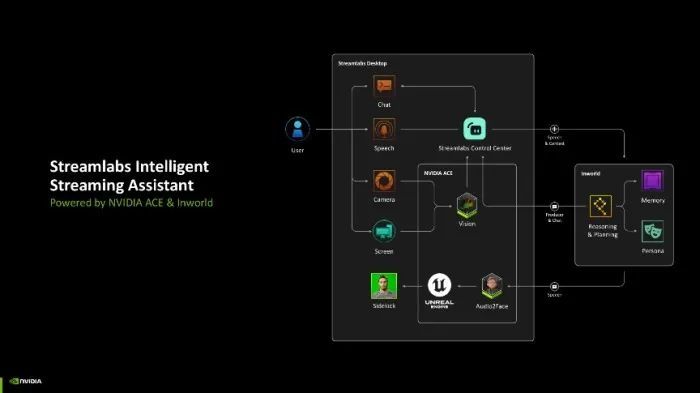
在游戏直播领域,RTX NIM相通证实着要紧作用。新推出的 Streamlabs Intelligent Streaming Assistant 不错为直播主提供智能的赞助功能,如同伴一样与直播主进行互动,对游戏内容作念出反应,或通过天然话语下达敕令。
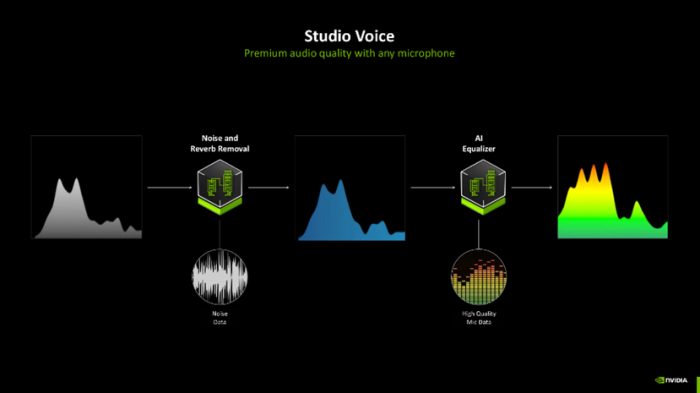
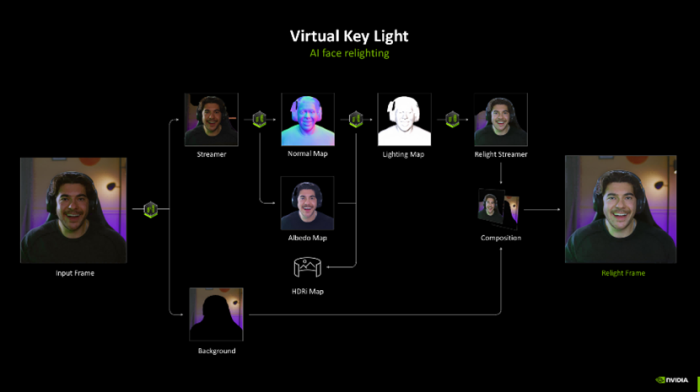
此外,NVIDIA Broadcast 直播软件也得到了功能更新,其 Studio Voice 功能不错通过 AI 分析去除布景杂音,复原语音的圆善频率响应范围,为直播主提供清醒、天然的语音证实。Virtual Key Light 功能则能够实时期析直播主的面部清明,自动诊疗打光效率,贬责清明不均匀、暗千里等问题,使直播主在镜头前长久保执最好形象。
创作领域:AI加快3D服务历程
在创意创作领域,NVIDIA在生成式AI领域取得了权贵进展,尤其是在3D服务历程的加快上。举例NVIDIA NIM带来了不少立异功能,改日Blender照旧不错与Comfy UI相斡旋,利用AI本领将3D场景迁移为传神的图像,这一立异将大大提高缱绻师的服务效率,另外对闲居用户也十分友好,你无需懂得详细的软件操作方式,也能生成传神的场景。

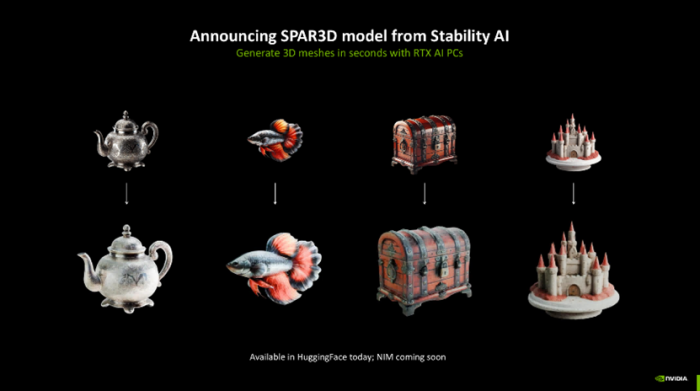
其次,Stability AI晓示了其SPAR3D模子,该模子能够利用RTX AI PC在几秒钟内从单张图像生成3D物体的圆善结构而且不错实时裁剪。
性能方面,NVIDIA也强调了,要是你使用的是GeForce RTX 50系列,生成式AI加快3D服务历程最高能够提高1.5倍的性能,权贵提高创意服务者的坐褥效率。

·结语
整合来看,GeForce RTX 50 系列显卡不单是是性能上的一次迭代,更像是本领范式的转型。它让显卡不再只是一个单纯的硬件器具,而是一个主动参与玩家体验的智能“助手”。不管是 DLSS 4 提高帧率、缩小延伸,照旧神经渲染本领带来的画质飞跃,这一代显卡齐在用骨子证实解释,它正在再行界说游戏体验的范畴。对玩家来说,此次升级无疑是一次“完胜”!玩家不再需要在“画质”和“性能”之间作念灾荒采选,因为 GeForce RTX 50 系列能够猖狂兼顾两者。不管是千里浸在4K 光追画面的细致画质,照旧在电竞赛场上见缝插针,GeForce RTX 50 系列齐能成为你的最好搭档。

照旧那句话,要是你是一位追求极致画质的硬核玩家,GeForce RTX 50 系列将会是你的不二之选。而关于那些还在等着“显卡降价”的不雅望者来说,这一代显卡简略会给你一个果决升级的意义。GeForce RTX 50 系列不单是是性能爆表的硬件,它更像是改日游戏体验的进口。它告诉咱们,显卡的作用不再只是单纯堆砌性能,而是用本领立异为玩家带来前所未有的新体验。改日已来,而GeForce RTX 50 系列,恰是改日的起初。